Research
Pushing the boundaries of AI-driven media localization. Our team reconstructs video content from the ground up.
JAM-Flow: Joint Audio-Motion Synthesis with Flow Matching
CineLingo Research Team • Seoul, South Korea
Abstract
The intrinsic link between facial motion and speech is often overlooked in video localization, where lip-sync, text-to-speech (TTS), and visual text translation are typically addressed as separate tasks. This paper introduces CineLingo, a unified framework to simultaneously synthesize and condition on both facial motion, speech, and visual elements for seamless video localization.
Our approach leverages advanced AI models and a novel Multi-Modal Localization Transformer (MM-LT) architecture. Trained with an end-to-end objective, CineLingo supports a wide array of conditioning inputs—including text, reference audio, and reference motion.
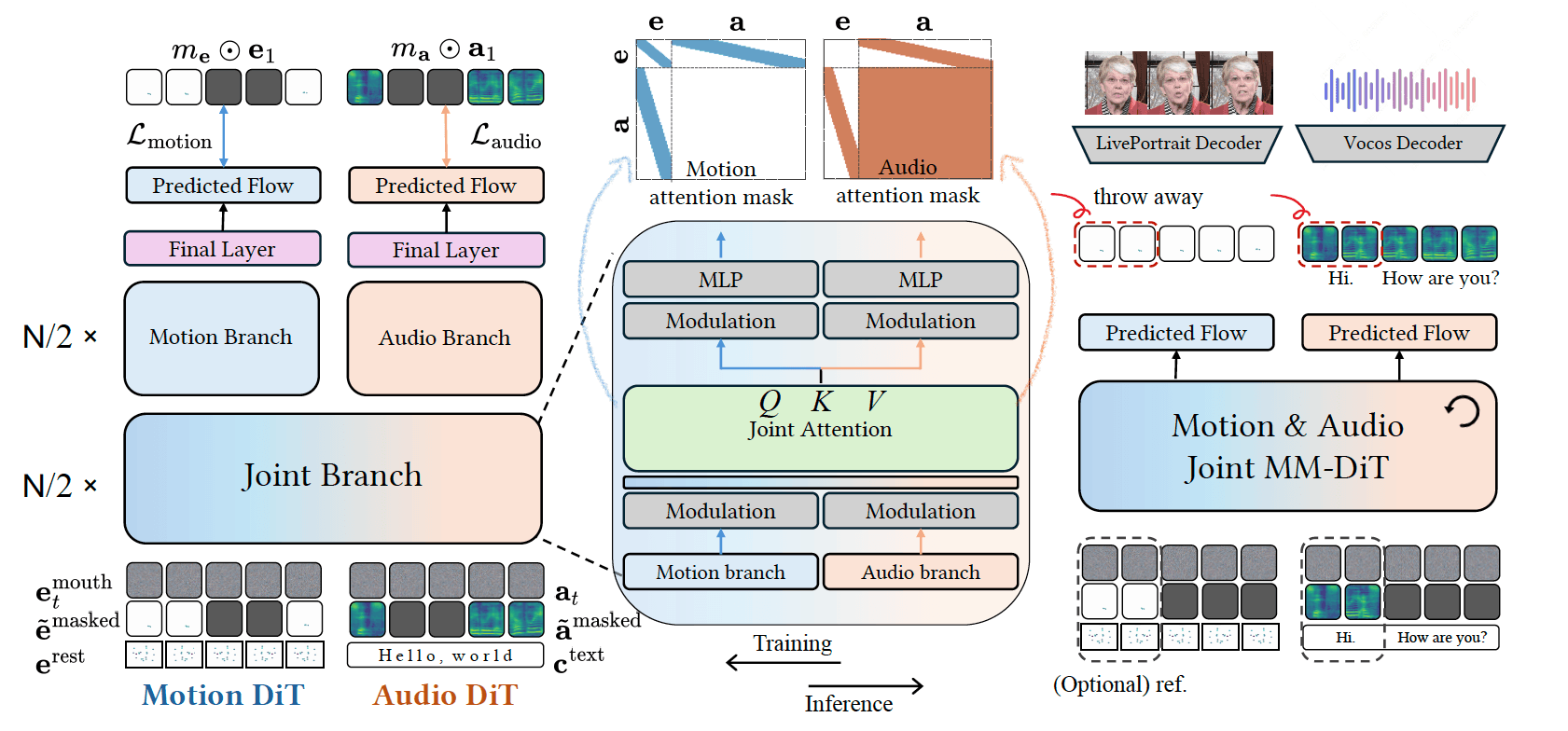
Figure 1: The training and inference pipeline of the JAM-Flow framework.
TTS-CtrlNet: Time varying emotion aligned text-to-speech generation with ControlNet
CineLingo Research Team • Seoul, South Korea
Abstract
Recent advances in text-to-speech (TTS) have enabled natural speech synthesis, but fine-grained, time-varying emotion control remains challenging. We propose the first ControlNet-based approach for controlling flow-matching TTS (TTS-CtrlNet).
We show that TTS-CtrlNet can boost the pretrained large TTS model by adding intuitive, scalable, and time-varying emotion control while inheriting the ability of the original model (e.g., zero-shot voice cloning & naturalness).
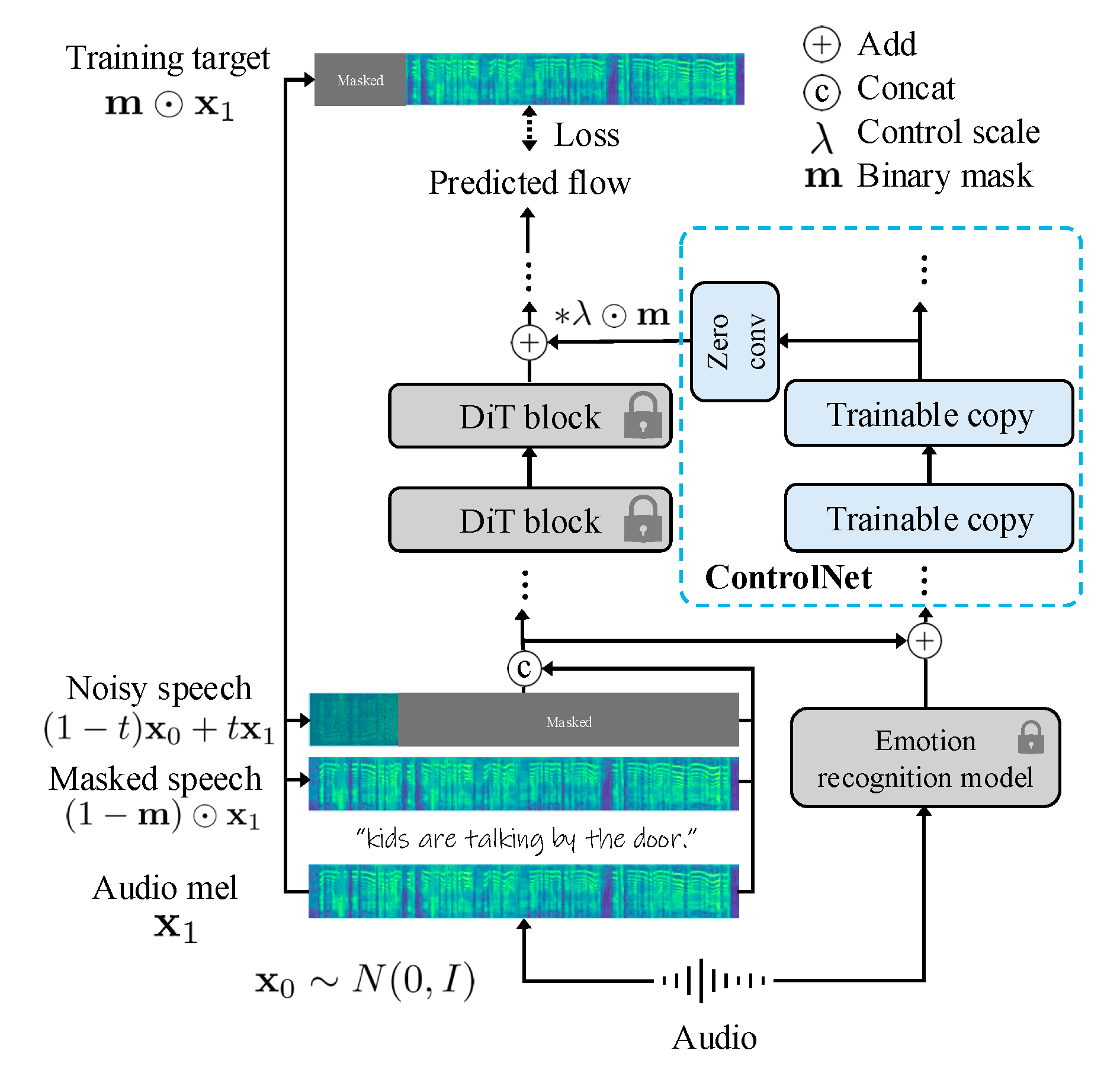
Figure 2: The training and inference pipeline of the TTS-CtrlNet framework.
Our Research Areas
Agent-based Translation
We use AI agents to perform high-quality, context-aware translation that adapts to content genre, tone, and culture. Our agents understand the broader context for intelligent decisions.
Text-to-Speech (TTS)
Our custom TTS systems produce native-level voices tailored to tone, timing, and character consistency. We leverage large language models for voices that sound natural.
Lip-sync Modeling
We build models that align facial movements with translated speech — frame-accurate and emotion-preserving. We ensure that every lip movement matches the spoken words naturally.
On-Screen Text Translation
Combining inpainting with vision-language models, we reconstruct visual text to deliver seamless translations. Our system detects, translates, and replaces text while maintaining coherence.
Interested in joining our research team?